Страница SPSS макросов Кирилла
Здесь вы можете найти оригинальные SPSS макросы (SPSS macros) — программы, написанные на пользовательском языке IBM SPSS Statistics и полезные для тех, кто обрабатывает и анализирует данные этим статистическим пакетом.

Некоторые сведения и инструкции
- Пожалуйста, обязательно прочтите перед тем, как пользоваться: о SPSS макросах
- Полный список макросов
- Об авторе макросов
- Другие источники по SPSS: ссылки
Страница SPSS макросов Кирилла имеет приют на spsstool.net, крупнейшем ресурсе по программированию в SPSS, благодаря его создателю Рейналю Левеку (Raynald Levesque) и директору Антону Балабанову. Хотя страница является частью этого сайта, она автономна («stand-alone») и управляется ее собственным создателем, Кириллом Орловым.
Без согласия автора не публикуйте никакие из этих макросов и их документов-описаний. Применяйте же свободно. Когда сообщаете где-то о своем применении или делитесь с другими, пожалуйста не забывайте называть источник — эту страницу и автора.
Мелкие ревизии макросов могут не сопровождаться пометками об обновлении на странице или в описании. Пожалуйста, не стесняйтесь сообщать автору о найденных вами неполадках в макросах или вносить идеи и предложения. Я буду рад вашей обратной связи.
Пускайте макросы также из диалоговых окон
Вы можете пускать некоторые из моих макросов не только из окна синтаксиса, но и из диалоговых окон меню SPSS Statistics (версии 24 или выше с установленным Integration Plug-In for Python 3). Диалоговые окна - на англ. яз. Просто скачайте и установите этот пакет-расширение (Extension Bundle): KO_macros.spe. Данная версия 7, и больше макросов (процедур) планируется добавлять в будущие издания пакета-расширения.
Вот коллекции макросов
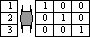
Categorical — Binary recodings
Перекодировка категориальных переменных в двоичные или наоборот. Собрание макросов для перевода категориальных данных в двоичные или обратно, например, создание фиктивных переменных или превращение наборов множественного ответа MRC (categorical multiple response) и MRD (dichotomous multiple response) – один тип в другой.

Multiple Response tools
Инструменты для наборов множественного ответа. Собрание разнообразных макросов для работы с переменными наборов множественного ответа – категориальных наборов (MRC) и дихотомических наборов (MRD), за исключением перекодировки их друг в друга (это см. в коллекции “Categorical – Binary recodings”).

Series Response tools
Инструменты для серии пунктов. Собрание макросов для «простого матричного вопроса», т.е. серии переменных с общим пулом альтернативных вариантов ответа (Single response series, SRS), - например набора пунктов, каждый из которых оценен по балльной шкале или проранжирован. Один макрос предназначен для данных ранжирования и переводит переменные в категориальный набор множественного ответа или обратно. Другой макрос предназначен для более общих задач перевода значений и переменных друг в друга и для обсчета повторяющихся значений. Третий макрос предназначен для ситуации, когда респонденты оценивали не все пункты, а те только, которые они предварительно выбрали, набивка же была сделана уплотненным (ускоренным) способом.
Horizontal tools
Некоторые горизонтальные операции. Собрание макросов, исполняющих некоторые нужные вещи (такие как стандартизация, сортировка, ранжирование, категоризация или подсчет частот и уникальных значений) внутри наблюдений, горизонтально.
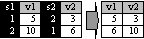
Derandomize tasks
Дерандомизация заданий. Если одни и те же задания (некоторые стимулы, например анкетные вопросы, тестируемые образцы или лечебные пользования) предъявлялись разным в испытуемым в разной последовательности, так что и в файл данных оказались набиты в порядке предъявления – «порядке проб», то макрос перестроит эти данные в унифицированный «порядок заданий», при котором каждая переменная содержит данные только одного задания.
Frequency weighting
Частотное взвешивание. Достижение нужных долевых размеров групп респондентов одномерным или многомерным (rim) взвешиванием. Можно выбрать общее N, наложить ограничение на взвешивание отдельных ячеек или наблюдений, взвесить несколько подвыборок параллельно, учесть начальные веса.
Categorical into Contrast
Категориальные переменные в контрастные. Создает из категориальных переменных контраст-переменные нескольких типов и их взаимодейственные переменные. Контраст-переменные нужны прежде всего тогда, когда нужно анализировать влияние качественных факторов методами, рассчитанными на количественные входящие (напр. линейная регрессия).
Various proximities
Разные меры близости. Вычисление большого числа мер близости или связи (сходства, расстояния, корреляции), многие из которых отсутствуют в SPSS. Среди них сходство Гауэра для сравнения респондентов по количественным и качественным признакам сразу.
Matrix comparisons
Различия внутри или между матрицами. Макросы вычисляют матрицу расстояний не между переменными или наблюдениями, а между матрицами близостей, – такими, как корреляционные или дистанционные, – либо между столбцами внутри таких матриц. Эти сравнения исследователю могут помочь: например, перед кластерным или факторным анализом.
Fit covariates
Подгонка переменных под матрицу коэффициентов. Макросы изменяют значения переменных так, чтобы переменные имели силу связи в соответствии с указанной пользователем матрицей (корреляций, ковариаций или кросс-произведений). Опция страхования от гетероскедастичности позволяет добиться гомоскедастичных связей.

Cumulative curves
Кумулятивные кривые. Макросы, связанные с анализом кумулятивных распределений. Один из них сравнивает кластерным анализом подвыборки по форме кумулятивного распределения в переменных. Другой макрос – для маркетинга – анализирует данные т.н. ценовой чувствительности (price sensitivity meter, PSM).
Internal clustering criteria
Внутренние кластерные критерии. Вычисление индексов, таких как Calinski–Harabasz, Davies–Bouldin, Cubic clustering criterion, Ratkowsky–Lance, C-Index, корреляция, гамма-статистика, Dunn (несколько типов), силуэт-статистика (несколько типов), AIC, BIC и других индексов, помогающих выбрать лучшее кластерное разбиение, в частности решить, сколько кластеров следует выделить в кластерном анализе.

Compare partitions
Сравнение классификаций/кластеризаций. Вычисление разных мер подобия группирований: внешние кластерные критерии, индексы правильности и согласия классификаций. Идентификация одинаковых или схожих групп между группированиями.
Euclidean space tools
Евклидовы правки и переводы. Макросы для матриц близостей, которые должны быть уложены в евклидово или метрическое пространство. Вы можете перевести сходства (типа ковариаций/корреляций или так трактуемые) геометрически корректно в расстояния или наоборот; подправить сходства или различия, не совсем удовлетворяющие пространству, в удовлетворяющие ему.

Job tools
Инструменты, облегчающие работу. Макросы, не связанные с конкретным анализом или обработкой, а служащие для ускорения всякого рода работ через синтаксис. Один из них является альтернативой по отношению к “SPSS Production Facility”, ускоряя производство таблиц и пр.

Regular clouds
Правильные облака. Создание многомерных данных с правильной, неслучайной структурой. В частности, такие данные можно понимать как полностью бескластерные, в отличие от данных, порожденных случайно. Полезны как модельные данные при изучении особенностей тех или иных статистических алгоритмов, например кластерного анализа.

Generate random clusters/mixtures
Случайные кластерные/смесные данные. Создание случайных данных, состоящих из четких кластеров или смесей (нечетких кластеров). Можно сделать эти облака круглыми или продолговатыми, гауссовыми или платикуртичными, регулировать их размеры и тесноту соприлегания. Отдельный макрос случайно поворачивает данные в пространстве.
Neighbourhood chains
Цепочки соседств. Из данных, показывающих парные отношения внутри набора объектов, извлекается информация о том, к какому объекту отсылает каждый данный объект «в первую очередь» или «сильнее всего». Так формируется траектория последовательных отсылок. Она показывается в виде таблицы (списка смежности) и дендрограммы.
Make Paired samples
Спаривание наблюдений двух выборок. Между двумя выборками или множествами делается оптимальное спаривание наблюдений, такое, что сумма внутрипарных различий минимизируется. Используется «венгерский алгоритм» сопряжения элементов от двух массивов в пары.
Procrustes analysis
Прокрустов анализ. Прокрустов анализ для двух конфигураций находит способ максимально совместить два облака точек в пространстве, при условии что точке одного облака заведомо назначена в соответствие точка другого. Остаточная величина несовпадения говорит об исходной степени нетождественности конфигураций. Анализ используется в задачах сравнения образов и сопоставления ординаций (к примеру матриц факторных нагрузок – для детекции одинаковых факторов).

Plot latents
Добавление латент как линий к облаку данных. Макросы показывают на диаграмме рассеяния данных их главные компоненты или дискриминанты – в виде линий, выложенных точками, значениями этих латент.
Impute missing data
Импутация пропущенных данных. Макросы выполняют колодное замещение (hot-deck imputation) пропущенных значений, заимствуя валидные значения у наблюдений, которые похожи на наблюдения с пропусками по неким фоновым характеристикам. Отдельный макрос выполняет произвольное, заданное пользователем заимствование значений у одних наблюдений другими наблюдениями.

MATRIX — END MATRIX functions
Функции для MATRIX – END MATRIX. Большое собрание полезных статистических, математических, переструктурирующих и иных функций для матричного сеанса в SPSS. Продвинутым пользователям в помощь анализу данных и написанию статистических алгоритмов.
Clustering
Кластеризация. Макросы для иерархического кластерного анализа (с опциями принуждения к предсуществующей структуре, преждевременной остановки, и другими), для вычисления расстояний между уже имеющимися группами/кластерами и для приписания новых объектов к ним. Макрос для инициирования центров кластеров в методе K-средних.
Compare proportions
Сравнение долей. Сравнение долей категорий, задаваемых одной категориальной переменной (переменная “единичного ответа”), либо долей положительного ответа в наборе двоичных переменных (набор “множественного ответа”). Выдача результатов форматирована похоже на Custom Tables, и процедура подходит для обработки опросных данных.
Compare sequences
Сравнение последовательностей или документов. Сравнение последовательностей элементов с вычислением меры попарного сходства между последовательностями. При сравнении можно учитывать или не учитывать цепочки элементов или их местоположение – т.е. сравнивать как крядные последовательности или просто как документы. Вы можете выбрать, каким путем устанавливать сходство: максимальное паросочетание, простое выравнивание, максимальная общая цепочка и др.
Marginal homogeneity
Тесты краевой однородности. Статистические критерии, тестирующие пару переменных как спаренные выборки на предмет одинаковости их краевых распределений или локаций в них.
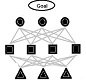
Analytic Hierarchy Process
Метод Анализа Иерархий Саати. Это исследование и анализ, которые позволяют принять решение по выбору из альтернатив, когда сформулирована конечная цель и построена иерархия подчиненных элементов, логически ведущих к этой цели, а альтернативы являются элементами нижнего уровня иерархии.

Clustering tendency
Тенденция кластерности. Некоторые методы разведки, которые позволяют предварительно судить до кластерного анализа, есть ли в данных кластеры. Блок-диагонализация матрицы расстояний между объектами может подсказать, сколько имеется кластеров. Статистика Хопкинса основана на симуляциях случайных бескластерных данных и сравнении их с наблюдаемыми данными.